5 Ways Poetiq's Meta-System Transforms LLM Coding Without Fine-Tuning
Imagine boosting an AI's coding ability without touching its code or training data. That's exactly what Poetiq's Meta-System achieves. By automatically crafting an optimized inference harness, this approach lifts multiple large language models (LLMs) on the demanding LiveCodeBench Pro benchmark—all without fine-tuning or accessing model internals. In this listicle, we break down the five essential things you need to know about this breakthrough.
1. LiveCodeBench Pro: Why It’s the True Test of Coding Intelligence
LiveCodeBench Pro (LCB Pro) isn't your typical benchmark. It's specifically designed to resist data contamination and overfitting—two common pitfalls that make many AI leaderboards unreliable. Problems come from competitive programming contests, and solutions are validated against a comprehensive testing framework that checks not just correctness but also memory limits and runtime constraints. The benchmark updates continuously, so models can't memorize answers. Focusing on C++ and creative problem-solving, LCB Pro measures complex logic and high-performance code, making it a gold standard for evaluating AI coding capability. Poetiq chose this rigorous environment to prove that a well-crafted harness can make any model perform better—no shortcuts allowed.
2. Three Task Categories: Positioning Coding as the Ultimate Blend
Poetiq frames LLM performance around three distinct axes: reasoning (benchmarked by ARC-AGI), retrieval (tested via Humanity’s Last Exam), and coding. Coding sits at the intersection of reasoning and retrieval, requiring models to find information, apply logic, and produce specialized procedural code. This perspective guided Poetiq's three-fold mission: first, show that a harness improves efficacy without fine-tuning; second, demonstrate that the Meta-System can recursively self-improve to create that harness; and third, prove the harness is model-agnostic—working on any LLM with zero modifications. By passing all three tests on LCB Pro, Poetiq validates a new path for enhancing AI performance without changing the underlying model.
3. What Is a Harness and Why It Matters for AI Coding
Think of a harness as the invisible scaffolding that guides a model's reasoning during inference. It's not a new model; it's the infrastructure that optimizes how prompts are structured, how the model iterates, and how outputs are validated. Poetiq's Meta-System automatically builds this harness by analyzing the task and testing multiple strategies. The result? The model doesn't get smarter—it gets better at using its existing capabilities. For coding, this means better handling of constraints, more efficient debugging, and less wasted computation. Because the harness is optimized externally, it can be swapped or upgraded independently of the base model, making it a cheap, flexible lever for performance gains.

4. Recursive Self-Improvement: The Engine of Model-Agnostic Gains
The magic of Poetiq's approach lies in recursive self-improvement. The Meta-System starts with a basic harness, then iteratively tests variations, learning from each run to refine its strategies. This process happens automatically, without human intervention. Because the harness is built from scratch for each model and each benchmark, it adapts to the model's strengths and weaknesses. The result is a harness that boosts any LLM, whether it's GPT-5.5 High or Gemini 3.1 Pro. This model-agnostic property is key: it means the same optimization framework can be applied to future models without re-engineering. Recursive self-improvement thus transforms the harness into a universal performance accelerator for coding tasks.
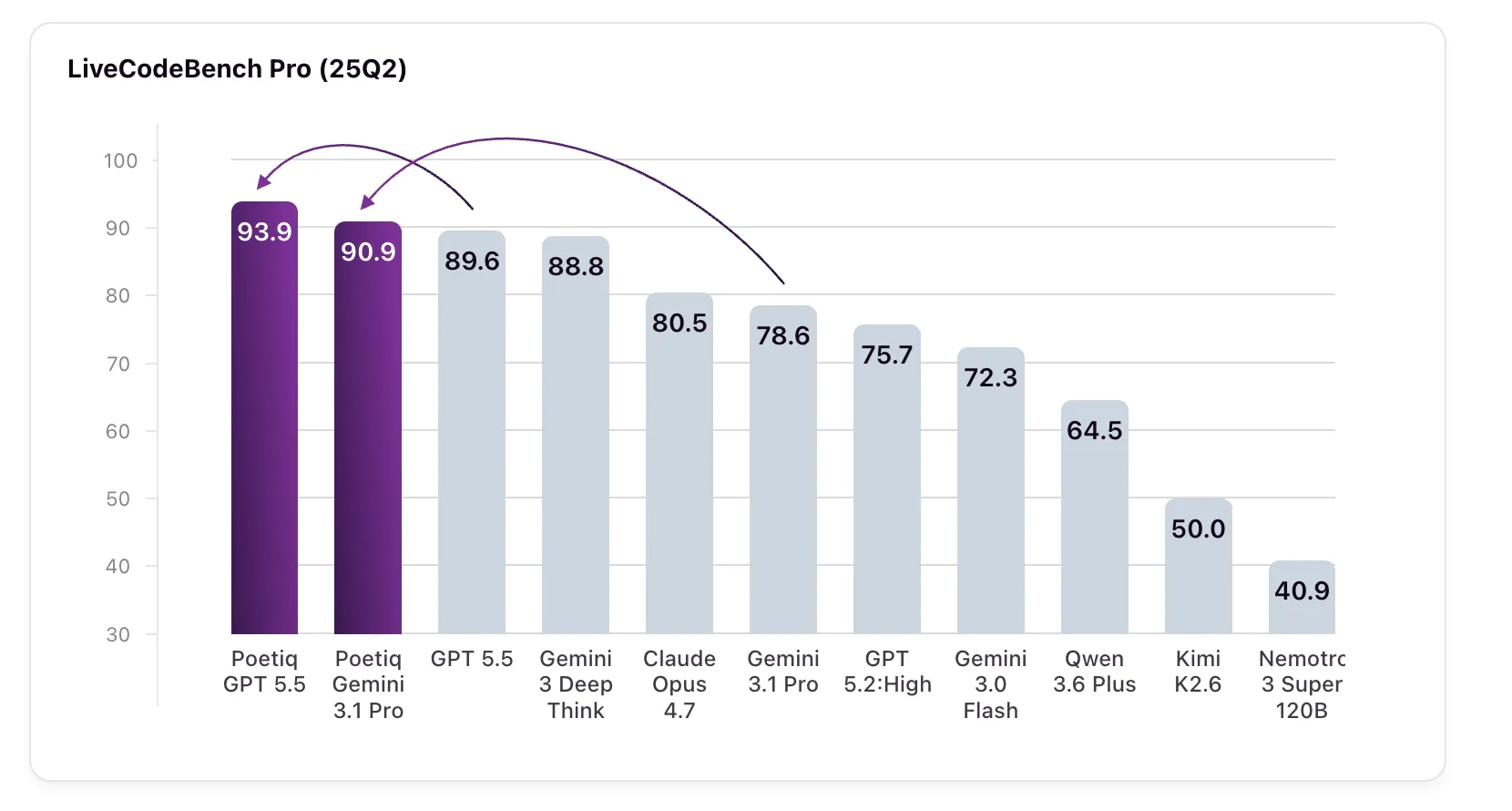
5. Stellar Results: GPT-5.5 High Scores 93.9% and Gemini 3.1 Pro Shines
The proof is in the numbers. GPT-5.5 High, with Poetiq's harness, jumped from a baseline 89.6% to 93.9% on LCB Pro (25Q2). Even more striking: Gemini 3.1 Pro—the model the harness was specifically optimized on—soared from 78.6% to 90.9%, surpassing Google's own Gemini 3 Deep Think (88.8%), a model not even accessible via API for external verification. These gains come without any fine-tuning or access to model internals. The harness, once built, works on any model; Poetiq tested it on several and saw across-the-board improvements. This suggests that the current bottleneck for LLM coding isn't the models themselves but the inference infrastructure surrounding them—and Poetiq has found a way to automate that optimization.
Poetiq's Meta-System signals a shift in AI enhancement: from modifying models to optimizing how we use them. By automatically building a model-agnostic harness that improves every tested LLM, the team has opened a door to scalable, low-cost performance boosts. As coding becomes the leading commercial AI application, such infrastructure innovations could prove more valuable than ever. The future may lie not in bigger or better models, but in smarter ways to harness their existing power.
Related Articles
- Microsoft Expands Xbox Full-Screen Experience to All Windows 11 PCs
- Safeguarding Enterprise Data in the Era of Generative AI: The Role of Privacy Proxies
- Google Clarifies Why Android AICore Storage Usage Can Spike Unexpectedly
- Google's New 'AI Ultra Lite' Subscription: What We Know So Far
- How to Deploy and Use Claude Opus 4.7 on Amazon Bedrock for Enhanced AI Performance
- Regain Your Privacy: A Step-by-Step Guide to Opting Out of AI Chatbot Training Data Use
- Breakthrough Algorithms Reveal Hidden Interactions in Large Language Models at Unprecedented Scale
- Leveraging AWS’s Latest AI Innovations: A Step-by-Step Guide